
「強化学習とは?」「強化学習の仕組みや具体例を知りたい」という方も多いでしょう。強化学習とは、AIが試行錯誤を通じて最適な行動を見つけ出す機械学習の一種です。
しかし、普段の生活において、実際にどこでどのように使用されているか分からないことも多いのではないでしょうか。
そこで本記事では、強化学習の基礎的な仕組みから、具体的な活用事例、主要なアルゴリズムなど幅広く解説します。
強化学習とは
強化学習とは、行動結果によって得られる成果や報酬を最大化する学習手法です。システムやロボットが試行錯誤を繰り返し、結果を分析していきながら最適な策を自らで見つけ出します。
強化学習をしているものの一例として、チェスや自動車などの自動運転のシミュレーションなどが挙げられます。
それぞれにおいて、最適な行動選択が求められ、行動と報酬を積み重ねることによって、自己学習機能を高めていくことが可能です。
強化学習の仕組み
環境と呼ばれる場に対してエージェントが行動を選択すると、その結果として「報酬」や「罰」が与えられます。エージェントは報酬を最大化するように行動方針を改善し続けることで、次第により良い戦略を獲得していきます。
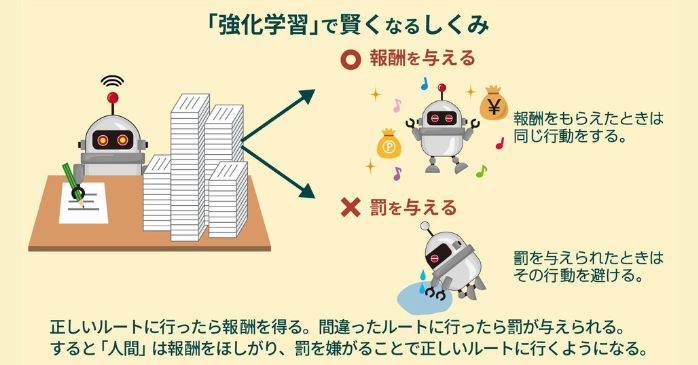
出典:ビジネスIT
例えば、ロボットに強化学習を用いると、最初は転びながらも少しずつ歩行が安定していきます。特徴は、正解データを事前に与えなくても学習が進む点であり、ゲームAIや自動運転など不確実な状況下での意思決定に広く活用されています。
行動において失敗した場合はそれを学び、試行錯誤することで大きな成果に導いていく仕組みです。
以下の記事では、生成AIについても解説していますので、あわせてご覧ください。
強化学習と他の学習方法の違い

与えられる環境の中で試行錯誤しながら自分で最善行動を発見していく強化学習ですが、 これは「教師あり学習」や「教師なし学習」などと異なり、正解データが用意されず、行動の積み重ねをすることで成果を生み出します。
以下では、強化学習と他の学習法方法の違いをそれぞれ解説します。
- 教師あり学習との違い
- 教師なし学習との違い
①教師あり学習との違い
教師あり学習は、「画像にある動物を識別する」「数字をもとに分析する」など、正解が存在するものです。そのため、正解ラベル付きデータによってモデルを作っていく学習方法となります。
それに対し、強化学習では正解データが存在しません。試行ごとに自らの選択結果からのみ学ぶ手法で、段階的に最良の選択に近づくものとなっています。
結果から得られる評価だけが手がかりとなり、自己判断能力の獲得に結びつきます。
②教師なし学習との違い
教師なし学習は、データの特徴や構造を自律的に分割や分類し、学習データに正解を与えない手法です。
正解と不正解が明確でない場合に効果がある学習方法です。教師なし学習の代表的な例に、顧客の共通点を見つけてグループ分けする「クラスタリング」があり、使用することで自動的にグループ分けが可能となります。
強化学習においては、グループ分けなどはせずに、適切な行動選択に焦点を当てることで、結果に基づき意思決定の良し悪しを学びます。
強化学習の代表的なアルゴリズム一覧

強化学習には、代表的なアルゴリズムとして3つ存在します。以下ではそれぞれ詳しく解説していきます。
| アルゴリズム名 | タイプ | ポリシー | 特徴 |
|---|---|---|---|
| Q学習 | 時間的差分 | オフポリシー |
|
| SARSA | 時間的差分 | オンポリシー |
|
| モンテカルロ法 | モンテカルロ | オンポリシー/オフポリシー |
|
①Q学習
Q学習は強化学習の基本的なアルゴリズムの一つで、AIエージェントが環境と相互作用しながら行動価値であるQ値を更新し、最適な行動方策を学習する手法です。
別名でQラーニングともいいます。3つの手法の中で一番多く用いられている手法で、行動価値関数であるQ関数を学習し、制御する仕組みとなっています。行動値関数Qが状態sにおいて行動aをとった場合に、その後の報酬をどれくらいもらえるのかを出力する関数です。
かみ砕くと、試行錯誤を重ねることによって、将来もらえる報酬を最大化していく流れであるということです。
②SARSA
SARSAは、強化学習の代表的なアルゴリズムの一つであり、実際にAIエージェントが選んだ行動に基づいてQ値を更新していく学習法です。
また、SARSAはQ学習と異なり「実際に選んだ行動」に基づいて価値を更新するため、現実的で安定した学習が可能です。不確実性が高く変化する環境でも安全に学習できるため、確実なシステム改善が必要とされるロボット制御や自動運転などの応用に適しています。
③モンテカルロ法
モンテカルロ法は、一連の行動が終わった後に、実際に得られた報酬の累積を平均して状態や行動の価値を推定する方法です。
この方法は、環境における詳細なモデルを必要とせず、実際の経験に基づいて価値を学習できる点が特徴です。数多くの試行錯誤の上でデータを集めるため、短期的な結果に左右されず長期的な効果を評価することが可能といわれています。
強化学習でできること

ここまで強化学習の概要や実際のアルゴリズムの特徴を解説してきましたが、実際のところは強化学習によって、どのようなことができるのでしょうか。分野ごとに詳しく解説します。
- ゲーム
- 自動運転
- ロボット制御
- 金融・トレーディング
- 医療・ヘルスケア
①ゲーム
ゲーム分野での強化学習は、囲碁や将棋など、複雑な戦略立案や未知の状況の攻略を自律的に進める能力が重視されています。
報酬設計を工夫することで、高得点や勝敗の最大化に必要な動きを効率よく学ぶことが可能です。AlphaGoが囲碁プロに勝利したように、人間の経験を凌駕する新しい発想や手法が登場しています。
シミュレーション回数を大幅に増やせるデジタル空間に強化学習を導入すると、最適戦略の創出速度が向上します。
②自動運転
自動運転における強化学習は、複雑な道路状況への柔軟な判断や、車両同士の衝突回避策の自動獲得に役立っています。車両や車周辺のセンサーデータをもとに、最適な経路や速度を確実に調整する点が強みです。
実際の交通環境を模したシミュレーションで何度も検証していくことにより、状況ごとに適切な操作ができるようにしています。また、急な天候変化や予期しない障害にも動的に対応する能力が鍛えられ、安全性の高い自動運転システムを支えています。
③ロボット制御
ロボット制御における強化学習は、作業効率の向上と複雑な動作最適化に直接結びついています。ロボットの移動や物をつかむ動作は、単純な命令だけでは制御が難しいとされています。
ロボット制御をするためには、各種センサーからの情報を活用し、反復学習を重ねることで、従来の手動設定よりも柔軟な動作の調整が必要です。
リアルタイムの細かな修正が必要とされ、制御ができるようになることで、物のピッキングや組み立ての自動化、協調作業ロボットでの最適な動作選択が進んでいます。
④金融・トレーディング
金融やトレーディングの分野では、強化学習が市場データを分析しながら最適な取引タイミングや資産配分の戦略を自律的に学習します。 これにより、ポートフォリオの効率的な運用や高頻度売買ができています。
実際に株式や為替の自動取引システムでは強化学習が活用され、複雑な市場環境にも適応可能です。また、過去の取引データをもとに試行錯誤し、リアルタイムの市場変動にも柔軟に対応することで継続的な収益向上にも貢献しています。
⑤医療・ヘルスケア
医療やヘルスケアの現場では、強化学習を活用して患者一人ひとりに最適な治療計画や薬剤提案などで強化学習が活かされています。患者の状態や治療経過をもとに、常に最良の選択肢を示せるため、医療の質が向上しコスト削減につながる効果が期待されます。
膨大な医療データ解析と継続的な学習により、効率的な医療運営や患者サポート体制の強化をはじめ、がん治療の投薬スケジュール調整やリハビリ支援装置の制御分野でも成果が期待できるでしょう。
以下の記事では、強化学習と関連の深い言語モデルの事例について紹介していますので、あわせてご覧ください。
強化学習の具体例・活用事例

強化学習が実際に使われている分野は多岐に渡っており、さまざまな事例があります。以下では強化学習の具体例と活用事例を解説します。
- 囲碁AI「AlphaGo」
- 自動運転技術への応用
- 金融取引アルゴリズム
①囲碁AI「AlphaGo」
囲碁AI「AlphaGo」は、従来のAIでは人間を圧倒することが難しかった複雑な対戦型ボードゲームを対象に、統計的に勝率の高い一手を見つける能力を獲得した事例です。
囲碁は可能な局面数が膨大で、教師あり学習だけでは網羅的な学習が困難でしたが、AlphaGoは「モンテカルロ木探索」と深層強化学習を統合することで、盤面評価と戦術予測を実現。プロ棋士との対局で勝利するなど、人間の直感や経験に頼っていた分野でもAIが新たな戦略を発見し、精度を飛躍的に高めました。
②自動運転技術への応用
自動運転車の開発現場では、リアルタイムで変化する道路状況や周囲の車両、信号、歩行者など多様な環境に柔軟に対応する制御判断が必要となります。
特に、車両が密集した交差点や幅が狭い道路、想定外の障害物回避といった高度な運転課題に対して、強化学習を使ったAIは、シミュレーション環境で試行錯誤を重ね「安全運転」および「効率的な走行経路」を学習。
初期段階では意図しない挙動や安全性への懸念がありましたが、報酬関数の設計やシミュレータによる反復学習により、複雑な状況下での正しい判断が可能になりつつあります。
③金融取引アルゴリズム
金融業界では、株式や為替取引のアルゴリズムに強化学習が応用されています。
価格変動が激しい市場で利益最大化を目指すトレーディング戦略の構築は複雑ですが、強化学習エージェントは過去の市場データから報酬を指標に、最適な売買タイミングやポートフォリオ配分を自律的に選択。
課題としては、環境が常に変化する金融市場で過学習やリスク増大が発生しうることですが、定期的なモデル更新やリスク制御の報酬関数設計によって、損失抑制や市場変化への柔軟な適応が進み、実際に利益率の向上やリスク低減に役立つ取引支援が実現しています。
強化学習を短期間で学べるおすすめセミナー

「強化学習を効率よく学びたい」という方は、「強化学習プログラミングセミナー」がおすすめです。AI学習未経験者でも基礎から応用までを体系的に習得できる集中型の講習であり、強化学習の仕組みやQ学習・DQNなどの代表的なアルゴリズムを理解できます。
また、実際のプログラム実装やシミュレーション環境構築までを体験できる内容になっています。基礎編では強化学習の基本概念やライブラリの使い方、Qテーブルの更新方法などを学習。応用編ではロボットアームの動作最適化やゲームAIへの応用、CNNを用いた画像識別強化学習まで実装可能になることを目指します。
受講者には113ページにわたるオリジナル教材「強化学習プログラミングセミナーガイド」が配布され、復習や実務への応用に役立つ参考書として活用できるため、効率的にスキルアップを図りたい方におすすめの実践的なセミナーです。
| セミナー名 | 強化学習プログラミングセミナー |
|---|---|
| 運営元 | GETT Proskill(ゲット プロスキル) |
| 価格(税込) | 35,200円〜 |
| 開催期間 | 1日間 |
| 受講形式 | eラーニング |
強化学習についてのまとめ
本記事では、AIの強化学習の基本的な仕組みや代表的なアルゴリズム、身近な場所において幅広い活用事例があることを紹介しました。
強化学習は、AIエージェントが試行錯誤を繰り返しながら最適な行動を学び、多くの分野で応用されています。普段の試行錯誤とともに、仮想空間やシミュレーションを活用することでより高度なシステムに成長でき、ビジネスでの効果を最大化することも可能となるでしょう。
強化学習によるシステムの発展は、今以上に多くの業界や生活において革新をもたらすことが期待されています。