
「DQN」と聞いて、インターネットスラングを思い浮かべる方も多いのではないでしょうか。この「DQN」は、テレビ番組『目撃!ドキュン』に由来し、非常識な行動をする人を指す言葉として広く認識されています。
しかし、AIの世界で使われるDQNは、まったく別の意味を持つ言葉で、偶然同じ名前ですが両者に関連は一切ありません。
この記事では、AIのDQNについてわかりやすく解説します。
機械学習やQ学習といった関連性の深い項目と結びつけながら、その仕組みをお伝えするので、DQNについて詳しく知りたい方、最新のAI技術の裏側を知りたい方は、ぜひ参考にしてください。
そもそもDQNとは?
DQNは、Google傘下のGoogle DeepMindが2015年に発表した機械学習の一つです。
DQNという言葉は、「Deep Q-Network(ディープ・キュー・ネットワーク)」の略で、その名の通り、Q学習にディープラーニングの技術を組み合わせ、ニューラルネットワークを用いてQ関数を近似するモデルです。
DQNの登場により、AI自身が、ゲームをプレイしながら攻略法を編み出せるようになり、ゲームAIやロボット制御は大きく進歩しました。実際にAtari2600の49種類のゲームで試され、そのうち29種類ではプロゲーマーよりも上手にプレイしてしまったのです。
DQNの歴史

続いて、DQNについて理解を深めるために、その誕生の背景や歴史を見ていきましょう。
DQN誕生の背景
DQNの研究は、2012年に画像認識コンテスト「AlexNet」の成功でディープラーニングが注目されたことから始まりました。
しかし、当時ディープラーニングと強化学習の代表的な手法である「Q学習」を組み合わせることは、多くの研究者にとって不可能だと考えられていました。なぜなら、複雑な環境を扱うと膨大な情報量になり、学習が安定しなくなるという課題があったからです。
DQNの歴史的転換点
この状況を変えたのが、2013年にGoogle DeepMindが導入した「経験再生」です。
この画期的な仕組みによって学習の安定化に成功。そして、2015年に科学誌『Nature』で、DQNがAtariゲームでプロゲーマーを上回る成果を達成したことが発表され、世界に衝撃を与えました。
DQNの成果の広がり
この成功は、囲碁で人間のトップ棋士を破り世界を驚かせた囲碁AI「AlphaGo」、ビデオゲーム『スタークラフト2』でプロゲーマーを凌駕した「AlphaStar」といったAI技術の発展へとつながっていったのです。
そして現在、私たちの日常に溶け込んでいる「自動運転車」「家庭用ロボット掃除機」などの、実用的な分野で活用されはじめています。
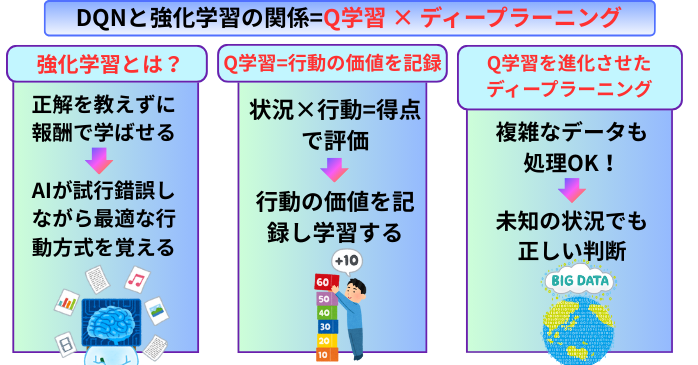
DQNと強化学習の関係
続いて、DQNと強化学習の関係を見てみましょう。ここでは、DQNと強化学習の関係が上手く紐づくように、以下の3つに分けて段階的に解説していきます。
- 強化学習とは
- Q学習との関係
- ディープラーニングによるQ学習の進化
①強化学習とは
まず、強化学習についてお伝えします。強化学習とは、以下の様に分類される機械学習の一つで、エージェント(学習する存在)が環境の中で試行錯誤を繰り返し、報酬を最大化するように学びます。
- 教師あり学習(正解データと照らし合わせて学ぶ)
- 教師なし学習(正解データがなく、データの特徴から学ぶ)
- 強化学習(正解が与えられない状況で、行動の結果から学ぶ)
例として、犬のしつけを考えてみましょう。
- 犬が「おすわり」できたらおやつ(=報酬)をあげる
- 間違った行動には何も与えない
犬は、この繰り返しにより「この行動をすると良いことがある」と学習していきます。これが強化学習の基本的な考え方です。
強化学習への理解を深めたい方は、強化学習プログラミングセミナーがおすすめです。
このセミナーは、短期集中型で、コスト&時間効率良く学べる初心者向けカリキュラムです。基礎からゲームの強化学習プログラムなど、実践レベルまで効率的にスキルアップできます。
強化学習については、以下の記事でも詳しく解説していますので、ぜひご一読ください。
②Q学習との関係
強化学習の中でも代表的なのが「Q学習」です。ここでは、ある状態と行動の組み合わせごとに「将来の報酬の見込み(Q値)」を表(Qテーブル)に記録します。エージェントはこの表をもとに、Q値が最も高い行動を選び、効率的に目標を達成しようとします。
例として、掃除ロボットを考えてみましょう。
| ステップ | 内容 |
| 1. 状態 | 掃除ロボットが現在いる状況(「部屋の位置」、「掃除済み、未掃除の箇所」など) |
| 2. 行動 | 前進、後退、右回転、左回転」など、ロボットがとる具体的な動作 |
| 3. Q値 | ある状態のときに、特定の行動をとった場合に得られる掃除の効率を示す数値 |
掃除ロボットは、このQテーブルに記録・更新しながら、部屋全体を効率的に掃除する最適な経路を学習します。
しかし、このQ値の表には「次元の呪い」と呼ばれる課題点もありました。つまり、学習を重ねることで表のサイズが非現実的に巨大になった場合、管理も学習もできなくなってしまうのです。
次元の呪い:データの次元の増大とともに計算量が膨れ上がること
③ディープラーニングによるQ学習の進化
そこで使われたのが、大量のデータから複雑なパターンを見つけるのが得意なディープラーニングです。
このディープラーニングを利用することで、膨大なQテーブルを丸ごと保存する代わりに、ニューラルネットワークがQ値を近似(複雑な関係を簡潔に表現)できるようになりました。
つまり、すべてのQ値を記録しておくのではなく、経験から学んだルールを使ってQ値を推測することで、未知の状況にも柔軟に対応できるのです。イメージとしては、以下のような感じです。
- Qテーブル=「日本全国の地図が載った分厚い地図帳」
- ニューラルネットワーク=「道案内が得意なAIカーナビ」
分厚い地図帳で目的地までの道を一つひとつ調べるのは大変ですが、AIカーナビなら過去の通行データから「この場所からなら、どの道が最も速いか」と瞬時に計算してくれます。
これによって、画像のような複雑なデータも処理できるようになり、未知の状況でも「似た経験」から正しい判断を下せるようになりました。
まとめると、DQNとは、強化学習のQ学習における課題点(膨大な情報量への限界)を克服するために、ディープラーニングを組み合わせ、AIの性能を飛躍的に向上させた技術なのです。
DQNの学習を安定させる工夫
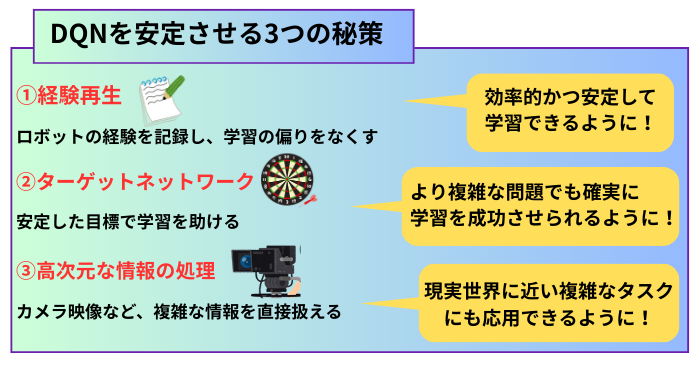
このように、ディープラーニングと強化学習を組み合わせることで大きな進歩を遂げました。そこで生まれた技術がDQNですが、そのままでは学習が不安定になりがちであったため、以下のような工夫を取り入れています。
- 経験再生(Experience Replay)
- ターゲットネットワーク
- 高次元な情報の処理
①経験再生(Experience Replay)
経験再生は、ロボットの経験(行動と結果)を一時的に記録しておき、学習時にはその中からランダムに選び出して使うことです。これにより、同じような経験ばかりを連続して学習するのを防ぎ、様々なデータからバランス良く学んでいきます。
②ターゲットネットワーク
ターゲットネットワークは、学習に使うメインのネットワークとは別に、「目標」を定めるための固定されたネットワークのことです。これにより、目標が頻繁に変わることで学習が混乱するのを防ぎ、安定した目標に向かってじっくりと学習できます。
③高次元な情報の処理
高次元な情報の処理とは、画像やセンサーデータのような膨大で複雑な情報を入力として取り込み、畳み込みニューラルネットワーク(CNN)がそこから特徴を抽出することです。これにより、DQNは整理された情報をもとに状況を判断し、適切な行動を選べるようになりました。
DQNの学習方法
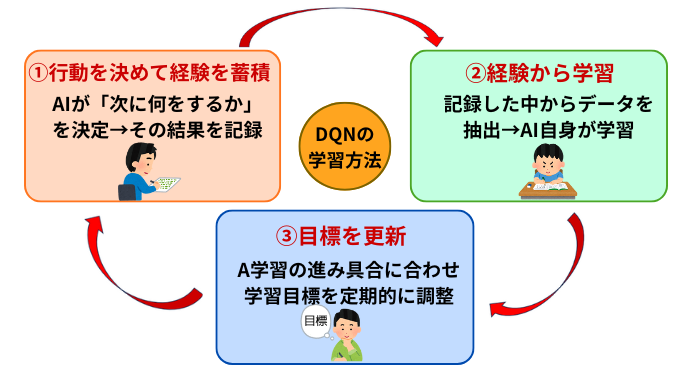
続いて、DQNがこれらの工夫によって学習を安定させた結果、どのような流れで学習を進めていくのか、具体的な方法を見ていきましょう。
DQNの学習は、大きく3つのステップで考えられます。
- 行動を決めて経験を蓄積する
- 経験から学ぶ
- 目標を更新する
①行動を決めて経験を蓄積する
まず、AIは今の状況を見て「次に何をするか」を決めます。この際、常に最も良さそうな行動ばかり選ぶと、新しい方法を見つけられません。
そこで、イプシロン・グリーディー法(ε-greedy法) を使い、たまにはランダムな行動も選びながら、未知のやり方も試し、学習の幅を広げていくのです。行動の結果は、まとめて経験として記録しておきます。
②経験から学ぶ
次のステップでは、蓄積した経験を使って学習します。このとき、記録しておいた経験からランダムにデータを取り出して学習します。この手法が、先ほどお伝えした経験再生(Experience Replay) です。
また、目標のQ値をターゲットネットワークで計算し、現在のQ値をQ-networkで計算することで、学習を安定させます。そして、実際の結果と目標を比べて、少しずつ行動の選び方を調整していくのです。
③目標を更新する
最後は、学習の進捗によって変化した目標を更新していきます。学習が進むと判断基準も変わるため、定期的にターゲットネットワークを最新情報に更新しなければいけません。
具体的には、設定したステップ数ごとに、学習が進んだQ-networkの重みをターゲットネットワークにコピーして更新します。これにより、安定した学習を維持するのです。
この3つを繰り返すことで、DQNは「賢いAI」へと成長し、未知の状況でも上手に行動できるようになります。
効率的&実践的に学べる!強化学習プログラミングセミナー
このように、DQNは複雑な仕組みで学習を安定させていますが、その応用は多岐にわたります。
強化学習プログラミングセミナーは、こうした強化学習やプログラミングの実装スキルを、未経験からでも短期間で習得できる効率的なカリキュラムです。
ロボットアームの動作最適化プログラム、ゲームAIの実装、CNN(畳み込みニューラルネットワーク)を活用した画像による状況判断など、実践レベルまで幅広くカバーしています。
セミナー名 強化学習プログラミングセミナー 運営元 GETT Proskill(ゲット プロスキル) 価格(税込) 35,200円〜 開催期間 1日間 受講形式 eラーニング
DQNの応用事例
DQNに代表される強化学習は、自動運転の性能向上にも大きく貢献しています。
従来の模倣学習(人間の運転を真似る方法)では、人間が想定しないような事態に対応できませんでしたが、強化学習は試行錯誤を通じて失敗から学び、エラーからの回復能力を大幅に高めました。
ここでは、自動運転にスポットを当て、ソニーAIが開発したレーシングAI「GT Sophy」を見てみましょう。
- トップレーサーを凌駕した走行
- 仮想空間でのシミュレーションも実現
トップレーサーを凌駕した走行
ソニーAIの「GT Sophy」は、人間のトップレーサーを上回る走行を可能にしたことで知られています。このモデルは、膨大なシミュレーション環境で数十億回の走行を繰り返し、極限のブレーキングや他車との駆け引きまで自ら学び取りました。
従来の模倣学習では再現できない戦略、超人的な判断力を備えたことが、大きな成果といえます。
仮想空間でのシミュレーションも実現
さらに、チューリングが取り組む「3D Gaussian Splatting」を使ったシミュレーション基盤では、現実の公道をフォトリアルに再構成し、仮想空間で自由なシナリオを生成可能にしました。
これにより、実際には危険で収集できない衝突データや、想定外の交通シーンも安全に学習素材として取り込めます。こうした取り組みは、自動運転AIが現実の多様な環境に適応し続けるための土台となりつつあります。
参照:チューリング株式会社
ソニーAIは、ゲームAIやロボティクス、音楽・映像など、AIを活用した様々なジャンルで事業を展開しています。以下の記事は、ソニーAIのサービス内容について詳しく解説しているので、ぜひこの機会にご一読ください。
DQNについてまとめ
自動運転や金融取引、ロボット制御など、DQNはすでに私たちの生活のあらゆる場面で活用され始めています。DQNの学習方法を理解し、実践と応用を重ねることで、今後のAI時代を生き抜くための重要な応用力が身につくでしょう。